

Disclosure: This article contains some affiliate links. If you sign up through them, I earn a small commission that helps keep this blog running.
The term "AI Wrapper" used to be a point of criticism in the developer community—a label for products seen as "thin" or lacking original IP. But as we move through 2026, that perspective has fundamentally shifted. Some of the most profitable bootstrapped Micro-SaaS companies today are essentially highly optimized user interfaces built on top of powerful Large Language Models (LLMs).
At DevMorph, we've realized that if you can solve a specific workflow problem for a niche audience, you don't need to build the model from scratch—you just need to engineer the best orchestration and user experience around it. The real value in 2026 lies in Context and UX, not just the raw API call.
Over the past year, our focus has shifted toward architecting these custom AI applications for high-ticket clients. The secret to a successful AI SaaS isn't burning millions to train a foundation model; it is about seamless architecture, rapid token streaming, and cost-effective infrastructure. Today, I am breaking down the exact SvelteKit and Node.js stack we use to launch production-ready AI tools over a single weekend.
The 2026 AI SaaS Tech Stack
Choosing the right stack determines how fast you can iterate. In the world of AI, where features become obsolete in weeks, speed is your only moat.
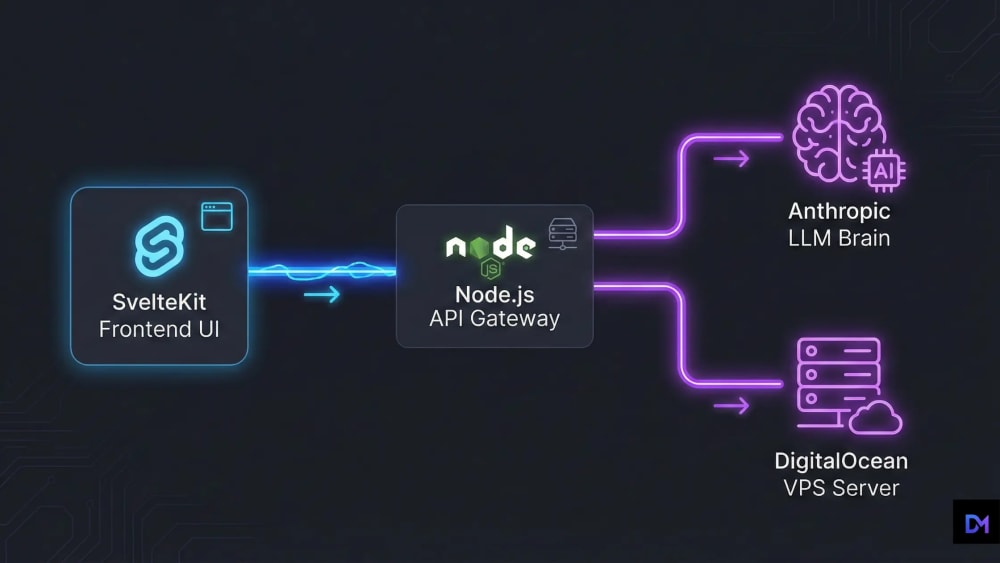
- Frontend: SvelteKit. When streaming real-time tokens, reactivity is everything. As we proved in our SvelteKit vs Next.js 16 Benchmarks, Svelte’s compiler-based reactivity handles high-frequency UI updates without the Virtual DOM overhead that slows down React.
- Backend: Node.js (Express/Fastify). We use a lightweight Node server as a secure proxy. A critical security rule: never call AI APIs directly from the browser. Keeping your API keys and system prompts on the server is the only way to prevent prompt injection and key theft.
- The Brains: Claude 4 (Latest). For complex logic and code generation, Anthropic’s latest models are our primary choice. After running extensive Claude vs Gemini Benchmarks, we found that Claude 4 handles structured JSON outputs and complex reasoning with much higher reliability for agentic workflows.
Streaming the AI Response (Backend Implementation)
The biggest UX mistake in AI development is making users wait for a full response. Perception of speed is more important than raw latency. You must implement Server-Sent Events (SSE) to stream tokens as they are generated. Here is the Node.js implementation we use to keep the interface snappy:
// server.js (Node.js API Route for AI Streaming)
import Anthropic from '@anthropic-ai/sdk';
import express from 'express';
const app = express();
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_KEY });
app.post('/api/generate', async (req, res) => {
const { prompt } = req.body;
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
const stream = await anthropic.messages.create({
max_tokens: 1024,
messages: [{ role: 'user', content: prompt }],
model: 'claude-4-latest',
stream: true,
});
for await (const chunk of stream) {
if (chunk.type === 'content_block_delta') {
res.write(`data: ${chunk.delta.text}\n\n`);
}
}
res.end();
});Data Sovereignty: Database and Auth
Managing chat history and user quotas is where most "wrappers" fail to scale. We prefer keeping full control over our data layer to avoid escalating managed-service costs. As detailed in our PocketBase self-hosting guide, running your own database alongside your Node server is up to 80% more cost-effective for high-read AI applications.
Deployment: The DigitalOcean Way
Deploying an AI SaaS on serverless platforms (like Vercel or AWS Lambda) can lead to execution timeouts during long-running AI generations and unpredictable bandwidth bills. For production tools, containerizing your stack with Docker and hosting it on a VPS is the most reliable and profitable method in 2026.
DevMorph Infrastructure Recommendation:
We host all our profitable AI tools on DigitalOcean Droplets. It gives us root access for local LLM caching, predictable monthly costs, and no execution time limits on long-running streaming connections.
Start Your AI SaaS on DigitalOceanFinal Thoughts
Building an AI prototype is simple, but scaling it securely with proper billing logic and database management is where the real business value is created. By leveraging SvelteKit for the frontend and a dedicated Node.js proxy on a VPS, you can build tools that aren't just wrappers, but essential components of your user's daily workflow.